c#
Q
c#でWindows Formアプリを作成しています。 Ctrl+ Shift+ マウスホイールスクロールで、panelを水平スクロールしたいです。 どうしたらよいですか?
A
Panelコントロールの水平スクロールをマウスホイール操作で行いたい場合、マウスホイールイベントのカスタムハンドラを作成することで実現できます。
まず、新しいMouseEventHandlerを作成し、それをPanelのMouseWheelイベントに接続します。次に、MouseEventArgsのDeltaプロパティを使ってスクロール量を計算し、PanelのHorizontalScrollプロパティを操作します。
以下に具体的なコードを示します。なお、Ctrl+Shiftキーが同時に押されていることを確認するために、Control.ModifierKeysプロパティも使用しています。
public Form1() { InitializeComponent(); // MouseWheelイベントにカスタムハンドラを接続 panel1.MouseWheel += new MouseEventHandler(panel1_MouseWheel); } private void panel1_MouseWheel(object sender, MouseEventArgs e) { // Ctrl+Shiftが同時に押されているか確認 if (Control.ModifierKeys == (Keys.Control | Keys.Shift)) { // e.Deltaは通常、-120か120です(ユーザーが下にスクロールすると-120、上にスクロールすると120) // そのため、ここではスクロール方向を反転し、適切なスクロール量を得るために120で割っています int newScrollValue = panel1.HorizontalScroll.Value + e.Delta / 120; // スクロール値が0未満にならないように、最小値を0に設定 newScrollValue = Math.Max(0, newScrollValue); // スクロール値が最大値を超えないように、最大値を設定 newScrollValue = Math.Min(newScrollValue, panel1.HorizontalScroll.Maximum); // 新しいスクロール値を設定 panel1.HorizontalScroll.Value = newScrollValue; // イベントが親コントロールにバブルアップするのを防ぐ ((HandledMouseEventArgs)e).Handled = true; } }
Q
Formで表をつくったら、デフォルトの挙動でCtrl + マウスホイールで水平スクロールされました。 これをCtrl Shift Scrollに上書きできますか?
A
マウスのホイール操作とキーボードの修飾キー(CtrlやShift)との組み合わせでスクロール動作を変更したい場合、PanelコントロールのMouseWheelイベントを扱うカスタムハンドラを作成することができます。具体的には、Control.ModifierKeysプロパティを使用して特定のキーが押されているかどうかを判断し、それに応じてスクロール操作を行います。
以下に、Ctrl+Shiftとマウスホイールの組み合わせで水平スクロールする例を示します:
public Form1() { InitializeComponent(); // MouseWheelイベントにカスタムハンドラを接続 panel1.MouseWheel += new MouseEventHandler(panel1_MouseWheel); } private void panel1_MouseWheel(object sender, MouseEventArgs e) { // Ctrl+Shiftが同時に押されているか確認 if (Control.ModifierKeys == (Keys.Control | Keys.Shift)) { // e.Deltaは通常、-120か120です(ユーザーが下にスクロールすると-120、上にスクロールすると120) // そのため、ここではスクロール方向を反転し、適切なスクロール量を得るために120で割っています int newScrollValue = panel1.HorizontalScroll.Value + e.Delta / 120; // スクロール値が0未満にならないように、最小値を0に設定 newScrollValue = Math.Max(0, newScrollValue); // スクロール値が最大値を超えないように、最大値を設定 newScrollValue = Math.Min(newScrollValue, panel1.HorizontalScroll.Maximum); // 新しいスクロール値を設定 panel1.HorizontalScroll.Value = newScrollValue; // イベントが親コントロールにバブルアップするのを防ぐ ((HandledMouseEventArgs)e).Handled = true; } else if(Control.ModifierKeys == (Keys.Control)) { // Ctrlが押されている場合、イベントを無視 ((HandledMouseEventArgs)e).Handled = true; } }
「イベントが親コントロールにバブルアップする」について説明します。
Windows Formsでは、コントロールが階層的に配置されている場合、特定のイベントは「バブルアップ」または「伝播」します。これは、子コントロールでイベントが処理されず、そのイベントが親コントロールまで伝わるというプロセスを指します。
たとえば、ネストされたPanelコントロール(つまり、他のPanelコントロールの内部にあるPanel)があるとします。この内部のPanelでMouseWheelイベントが発生した場合、そのイベントはまずそのPanelに伝わります。しかし、そのPanelでイベントが処理(Handled)されなかった場合、そのイベントは外側のPanelに「バブルアップ」します。これが続き、最終的にはFormレベルまでイベントが伝播します。
このバブルアップの挙動を制御するために、HandledMouseEventArgsクラスのHandledプロパティが提供されています。このプロパティがtrueに設定されると、そのイベントは「処理済み(Handled)」とみなされ、それ以上バブルアップしないようになります。
したがって、コードのこの部分:
((HandledMouseEventArgs)e).Handled = true;
は、「このイベントはすでに処理済みであるため、それ以上バブルアップさせない」という意味を持ちます。この結果、イベントが上位のコントロール(親コントロール)に伝播するのを防ぎ、予期せぬ動作を避けることができます。
Q
表などのテキストが小さいので大きくしたいという要望がありました。 フォントのサイズを大きくするにはどうしたらよいですか?
A
フォームや特定のコントロール(テキストボックス、ラベル、ボタンなど)のフォントサイズを変更するには、Fontプロパティを使用します。
たとえば、Form全体のフォントサイズを変更するには以下のようにします:
this.Font = new Font(this.Font.FontFamily, 20); // FontFamilyは同じままで、サイズを20に変更
特定のコントロール(ここではtextBox1)のフォントサイズを変更するには:
textBox1.Font = new Font(textBox1.Font.FontFamily, 20); // FontFamilyは同じままで、サイズを20に変更
また、DataGridView(表)のフォントサイズを変更するには:
dataGridView1.DefaultCellStyle.Font = new Font("Arial", 20);
この例では、Fontクラスの新しいインスタンスを作成し、そのインスタンスを対象のコントロールのFontプロパティに設定しています。Fontクラスのコンストラクタは、フォント名(FontFamily)とフォントサイズを引数として受け取ります。フォント名は既存のものをそのまま使用し(this.Font.FontFamilyやtextBox1.Font.FontFamily)、フォントサイズのみを新たに指定しています。
これにより、対象のコントロールのテキストが指定したサイズで表示されるようになります。
this.Font = new Font(this.Font.FontFamily, 20); // FontFamilyは同じままで、サイズを20に変更
このコードは通常、フォームがロードされるときに実行したいので、フォームの Load イベントハンドラに追加することが一般的です。
フォームのデザイナビューで、フォームを右クリックし、「プロパティ」ウィンドウを開いてください。そのウィンドウで「イベント」タブ(通常は稲妻のアイコン)をクリックし、「Load」イベントを探します。その隣の空欄をダブルクリックすると、イベントハンドラのスケルトンコードが自動的に作成され、コードビューが開きます。この Load イベントハンドラ内に、以下のコードを追加します:
private void Form1_Load(object sender, EventArgs e) { this.Font = new Font(this.Font.FontFamily, 20); // FontFamilyは同じままで、サイズを20に変更 }
これにより、フォームがロードされるときにフォントサイズが変更されます。
ただし、フォーム内に配置した各コントロール(テキストボックス、ラベル、ボタンなど)が個別にFontプロパティを設定している場合、それらのコントロールのフォントサイズはフォームのフォントサイズ設定の影響を受けません。その場合、各コントロールに対して個別にFontプロパティを設定する必要があります。
AtCoder入門 3-3
- [:contents]
- ABC
- ABC 220 b
- ABC 090 b
- ABC 068 b
- ABC 093 B B - Small and Large Integers
- ABC 208 B B - Factorial Yen Coin
- ABC 164 B - B - Battle
- ABC 200 B - B - 200th ABC-200
- ABC162 B - FizzBuzzSum
- ABC206 B - Savings
- ABC165 B - 1%
ABC
問題リンク↓
回答
回答リンク↓
振り返り
ABC 220 b
問題リンク↓
B - Base K
回答
回答リンク↓
Submission #41598161 - AtCoder Beginner Contest 220
振り返り
- 答えをint型でやってたら最初
WAがでた - 10 ^9 以上になりうるならば long long 型にするのが良さそう。
ABC 090 b
問題リンク↓
B - Palindromic Numbers
回答
回答リンク↓
Submission #41597002 - AtCoder Beginner Contest 090
振り返り
- エディタに考えを書きながらコーディングしてみた。
- 結構いい感じかもなので続けてみる。
- string型久しぶりに扱って忘れてたけど、ぱぱっと調べながらできてよかった。
- 文字列長取得できるよね?とか、配列的にアクセスできるよね?とからへんは覚えてたのはよかった。
ABC 068 b
回答
Submission #41596543 - AtCoder Beginner Contest 068
振り返り
- 特になし。
ABC 093 B B - Small and Large Integers
回答
Submission #41528487 - AtCoder Beginner Contest 093
振り返り
- もっと瞬殺で解ける様になりたい
- 頭の中だけで考えると全然考えがまとまらないので、今わかっている範囲で良いので、まずは書き出して行くことが大事だと思う。
- いきなり最適解を出す必要はなくて、分かっている条件とかパターンをつらつらと書き出していって、書き出したあと、まとめれるところまとめてきれいにすれば良いんだと思う。
ABC 208 B B - Factorial Yen Coin
回答
Submission #41501940 - AtCoder Beginner Contest 208
振り返り
- 急に難易度高くない?
- 少し時間かかったが、答えみずにとけた。
- vectorの使い方とか忘れていた。添字で一個ミスってた。よくありがち。
- 解説見ると難しいこと書いてあった。あとでよむと良いかも。
ABC 164 B - B - Battle
回答
Submission #41480333 - AtCoder Beginner Contest 164
振り返り
- とくに振り返ることなし。
ABC 200 B - B - 200th ABC-200
回答
Submission #41464806 - KYOCERA Programming Contest 2021(AtCoder Beginner Contest 200)
振り返り
- なんなく正解できた。
- もっとも大きい答えの場合のデータサイズの見積もりについては、あまり考慮できていない。
- とりあえず long longでやっときゃいけるやろ。とざっくり解いてしまっている。
ABC162 B - FizzBuzzSum
- ansの型をどうすれば良いのかわからなくてchatgptに質問した
- 結果、long long型にすればOKだった。
- はじめはdouble型にしていたが、倍精度浮動小数点になるので、
2.66666e+11とか出力されて駄目だった。 - longlong型は64bit整数型なので、答えは絶対整数になるはずだし、それでOKだった。
ABC206 B - Savings
問題
回答
Submission #41273909 - AtCoder Beginner Contest 206(Sponsored by Panasonic)
振り返り
- どの型だったら答えの値の最大値でも耐えうるかわからんかったのでとりあえず
long long型とした long long型の最大値はLONG_LONG_MAXでいけた。- 問題自体は独力で解けた。
ABC165 B - 1%
問題
回答
Submission #41310512 - AtCoder Beginner Contest 165
振り返り
- 正解できず。
ans = ans * 1.01;はNGans = ans + ans /100;はOK- その違いは、小数点以下切り捨てるかどうか
- ChatGPTさんいわく下記
これらの2つのコードの主な違いは、入力値xに到達するまでansを増加させる方法にあります。
コード1では、
ansはその値の1%を加算することで増加します(ans = ans + ans / 100;)。この方法は整数算術を使用していて、ans / 100が整数除算であるため、小数点以下の値は切り捨てられます。したがって、この方法ではansの増加はかなり遅くなります。コード2では、
ansはその値を1.01倍することで増加します(ans = ans * 1.01;)。これは浮動小数点数算術を使用しており、ansの増加はより速くなります。
したがって、入力値xが非常に大きい場合(例えば、あなたが提供したような974755271730884810)、コード1はコード2よりもはるかに多くのループを必要とします。これは、コード1がansの増加を整数算術で計算するため、小数点以下の値が切り捨てられ、増加が遅くなるためです。
AtCoder入門 3-2
結果
これ以外は解けた
振り返り
- まだ初級のところなので解けるが、典型90問のやつは駄目だった。
- 10minぐらい考えた?が解ける気がしない。
- 場合分け考えるときに偶数、奇数の場合分けしてみればいけるのでは?
- みたいな発想がない。
- 1列のときはどうなるんだろう?みたいな境界値について検討する発想がない。
- 発想があったとして、1列のときどうなるか、問題からは読み取れなくね?
典型の問題はtwitterにも解説が投稿されているっぽい。
問題文には下記文言がある。
イルミネーション全体に完全に含まれる 縦 2 × 横 2 の、4 つの LED を含む領域であって、点灯している LED が領域内に 2 つ以上あるものが存在する。
- 1行のときはここでいう 4つのLEDを含む領域であって というところに該当しないのでOKということっぽい。
- あと割り算、切り上げのときは+1して除算する。っていうのはなるほどなって感じ。
- 毎回 if文で分けてたので、今度からそれでやってみよう。
その他の感想
- 継続し易い構成になっている本だと思うので、ちびちびやっていきたい。
- 2周目やるときに、成長知ている感をエられれば嬉しいなぁ。
- んでもってまずは茶色になりたい
VBA
ChatGPTとの会話ログ。あとで精査
前提
下記のエクセルの表があります。
Excel表
MCompGrp | ID | GName | Code | | ----- | ----- | ---------- | | Head | 本社 | 〒xxx-xxxx | | Tokyo | 東京 | 〒yyy-yyyy |
実施したいこと
このエクセルシートを読み込んでXMLを出力VBAマクロを作成したいです。 上記の表の場合出力したいXMLは下記です。
<MCompGrp> <CompGrp> <ID>Head</ID> <GName>ソリューション</GName> <Code>〒xxx-xxxx</Code> </CompGrp> <CompGrp> <ID>Tokyo</ID> <GName>東京</GName> <Code>〒yyy-yyyy</Code> </CompGrp> </MCompGrp>
どの様にVBAコードを書けばいいですか?
ANS
以下に、指定されたエクセル表からXMLを出力するVBAマクロのコード例を示します。
Sub ExportToXML() Dim ws As Worksheet Dim xml As String Dim i As Long Dim lastRow As Long ' シート "MCompGrp" を選択 Set ws = ThisWorkbook.Sheets("MCompGrp") ' 最終行を取得 lastRow = ws.Cells(ws.Rows.Count, 1).End(xlUp).Row ' XMLのヘッダー xml = "<?xml version=""1.0"" encoding=""UTF-8""?>" & vbCrLf xml = xml & "<MCompGrp>" & vbCrLf ' 表のデータをXML形式に変換 For i = 2 To lastRow xml = xml & vbTab & "<CompGrp>" & vbCrLf xml = xml & vbTab & vbTab & "<ID>" & ws.Cells(i, 1).Value & "</ID>" & vbCrLf xml = xml & vbTab & vbTab & "<GName>" & ws.Cells(i, 2).Value & "</GName>" & vbCrLf xml = xml & vbTab & vbTab & "<Code>" & ws.Cells(i, 3).Value & "</Code>" & vbCrLf xml = xml & vbTab & "</CompGrp>" & vbCrLf Next i ' XMLのフッター xml = xml & "</MCompGrp>" & vbCrLf ' XMLをファイルに出力 Dim fileName As String Dim fso As Object Dim outputFile As Object fileName = ThisWorkbook.Path & "\output.xml" Set fso = CreateObject("Scripting.FileSystemObject") Set outputFile = fso.CreateTextFile(fileName, True, True) outputFile.Write xml outputFile.Close MsgBox "XMLファイルが出力されました。" End Sub
このコードは、以下の手順で動作します。
- "MCompGrp" シートを選択し、最終行を取得します。
- XMLのヘッダー部分を作成します。
- 表のデータを読み取り、XML形式に変換します。
- XMLのフッター部分を作成します。
- 変換したXMLをファイルに出力します。
- このマクロを実行すると、エクセルファイルと同じディレクトリに "output.xml" という名前のXMLファイルが生成されます。
Q
VBAマクロは表があるシートのExcel Object上に作成する予定です。 その場合はシートの選択は不要でしょうか?
A
Sub ExportToXML() Dim xml As String Dim i As Long Dim lastRow As Long ' 最終行を取得 lastRow = Me.Cells(Me.Rows.Count, 1).End(xlUp).Row ' XMLのヘッダー xml = "<?xml version=""1.0"" encoding=""UTF-8""?>" & vbCrLf xml = xml & "<MCompGrp>" & vbCrLf ' 表のデータをXML形式に変換 For i = 2 To lastRow xml = xml & vbTab & "<CompGrp>" & vbCrLf xml = xml & vbTab & vbTab & "<ID>" & Me.Cells(i, 1).Value & "</ID>" & vbCrLf xml = xml & vbTab & vbTab & "<GName>" & Me.Cells(i, 2).Value & "</GName>" & vbCrLf xml = xml & vbTab & vbTab & "<Code>" & Me.Cells(i, 3).Value & "</Code>" & vbCrLf xml = xml & vbTab & "</CompGrp>" & vbCrLf Next i ' XMLのフッター xml = xml & "</MCompGrp>" & vbCrLf ' XMLをファイルに出力 Dim fileName As String Dim fso As Object Dim outputFile As Object fileName = ThisWorkbook.Path & "\output.xml" Set fso = CreateObject("Scripting.FileSystemObject") Set outputFile = fso.CreateTextFile(fileName, True, True) outputFile.Write xml outputFile.Close MsgBox "XMLファイルが出力されました。" End Sub
このコードは、上記のコード例と同じように動作しますが、シート選択部分が Me キーワードを使用している点が異なります。これにより、マクロが配置されているシートに直接アクセスできます。
Q
エクセルのテーブル機能を使って、表にはテーブル名として「MCompGrp」と設定する予定です。 その場合、表から値を取得する方法は変わりますか?
A
Sub ExportToXML() Dim tbl As ListObject Dim xml As String Dim i As Long ' テーブル "MCompGrp" を選択 Set tbl = Me.ListObjects("MCompGrp") ' XMLのヘッダー xml = "<?xml version=""1.0"" encoding=""UTF-8""?>" & vbCrLf xml = xml & "<MCompGrp>" & vbCrLf ' 表のデータをXML形式に変換 For i = 1 To tbl.ListRows.Count xml = xml & vbTab & "<CompGrp>" & vbCrLf xml = xml & vbTab & vbTab & "<ID>" & tbl.DataBodyRange(i, 1).Value & "</ID>" & vbCrLf xml = xml & vbTab & vbTab & "<GName>" & tbl.DataBodyRange(i, 2).Value & "</GName>" & vbCrLf xml = xml & vbTab & vbTab & "<Code>" & tbl.DataBodyRange(i, 3).Value & "</Code>" & vbCrLf xml = xml & vbTab & "</CompGrp>" & vbCrLf Next i ' XMLのフッター xml = xml & "</MCompGrp>" & vbCrLf ' XMLをファイルに出力 Dim fileName As String Dim fso As Object Dim outputFile As Object fileName = ThisWorkbook.Path & "\output.xml" Set fso = CreateObject("Scripting.FileSystemObject") Set outputFile = fso.CreateTextFile(fileName, True, True) outputFile.Write xml outputFile.Close MsgBox "XMLファイルが出力されました。" End Sub
このコードは、以下の手順で動作します。
"MCompGrp" テーブルを選択します。 XMLのヘッダー部分を作成します。 テーブルのデータを読み取り、XML形式に変換します。 XMLのフッター部分を作成します。 変換したXMLをファイルに出力します。 このマクロを実行すると、エクセルファイルと同じディレクトリに "output.xml" という名前のXMLファイルが生成されます。
Q
A
おっしゃる通り、VBAでXMLを扱う場合、「MSXML」ライブラリを使用することが一般的です。また、XML DOMオブジェクトを使ってXML構造を操作することもできます。
上記のコード例では、シンプルなXMLを文字列として扱っていますが、XML DOMオブジェクトを使用してXMLを作成・操作することも可能です。
以下に、「Microsoft XML, v6.0」ライブラリを使用し、XML DOMオブジェクトを作成してXMLを出力するVBAマクロのコード例を示します。
Sub ExportToXML() Dim tbl As ListObject Dim i As Long ' テーブル "MCompGrp" を選択 Set tbl = Me.ListObjects("MCompGrp") ' XML DOMオブジェクトの初期化 Dim xmlDoc As New MSXML2.DOMDocument60 Dim xmlMCompGrp As IXMLDOMElement Dim xmlCompGrp As IXMLDOMElement Dim xmlNode As IXMLDOMElement xmlDoc.async = False xmlDoc.validateOnParse = False xmlDoc.resolveExternals = False ' ルート要素の作成 Set xmlMCompGrp = xmlDoc.createElement("MCompGrp") xmlDoc.appendChild xmlMCompGrp ' 表のデータをXML形式に変換 For i = 1 To tbl.ListRows.Count Set xmlCompGrp = xmlDoc.createElement("CompGrp") Set xmlNode = xmlDoc.createElement("ID") xmlNode.Text = tbl.DataBodyRange(i, 1).Value xmlCompGrp.appendChild xmlNode Set xmlNode = xmlDoc.createElement("GName") xmlNode.Text = tbl.DataBodyRange(i, 2).Value xmlCompGrp.appendChild xmlNode Set xmlNode = xmlDoc.createElement("Code") xmlNode.Text = tbl.DataBodyRange(i, 3).Value xmlCompGrp.appendChild xmlNode xmlMCompGrp.appendChild xmlCompGrp Next i ' XMLをファイルに出力 Dim fileName As String Dim fso As Object Dim outputFile As Object fileName = ThisWorkbook.Path & "\output.xml" Set fso = CreateObject("Scripting.FileSystemObject") Set outputFile = fso.CreateTextFile(fileName, True, True) outputFile.Write xmlDoc.XML outputFile.Close MsgBox "XMLファイルが出力されました。" End Sub
Q
XMLファイルの改行コードは"LF"である必要があるとききました。 上記VBAマクロで生成されるXMLファイルは問題ないですか?
A
ご指摘の通り、XMLファイルの改行コードは通常、"LF"(\n)が推奨されています。しかし、上記のVBAマクロでは、改行コードとして "CrLf"(\r\n)が使用されています。これは、Windows環境で一般的な改行コードです。
XMLファイルの改行コードを "LF" に統一するには、以下のようにコードを修正します。
Sub ExportToXML() ' 他のコードは変更なし ' XMLをファイルに出力 Dim fileName As String Dim fso As Object Dim outputFile As Object fileName = ThisWorkbook.Path & "\output.xml" Set fso = CreateObject("Scripting.FileSystemObject") Set outputFile = fso.CreateTextFile(fileName, True, True) ' 改行コードを LF に変更 Dim xmlLF As String xmlLF = Replace(xmlDoc.XML, vbCrLf, vbLf) outputFile.Write xmlLF outputFile.Close MsgBox "XMLファイルが出力されました。" End Sub
VBAで別シートの関数を呼び出す方法
前提
下記構成のエクセルファイルがある
シート
- Sheets1
- シート名: "シート1"
VBAの構成
- Sheets1(シート1)のマクロ
Public Function SheetOneFunc() MsgBox "This is SheetOneFunc." End Function
このとき標準モジュールから、SheetOneFunc()を呼び出したい
標準モジュールの関数の書き方
Sub Func() Application.Run ThisWorkbook.Worksheets("シート1").CodeName & ".SheetOneFunc" End Sub
このコードでは、ThisWorkbook.Worksheets("シート1") を使って "シート1" シートにアクセスし、その後に CodeName と .CParamMakeXML を連結して、Application.Run を使って SheetOneFunc 関数を直接呼び出している。
作業シート作成VBA
完成形イメージ
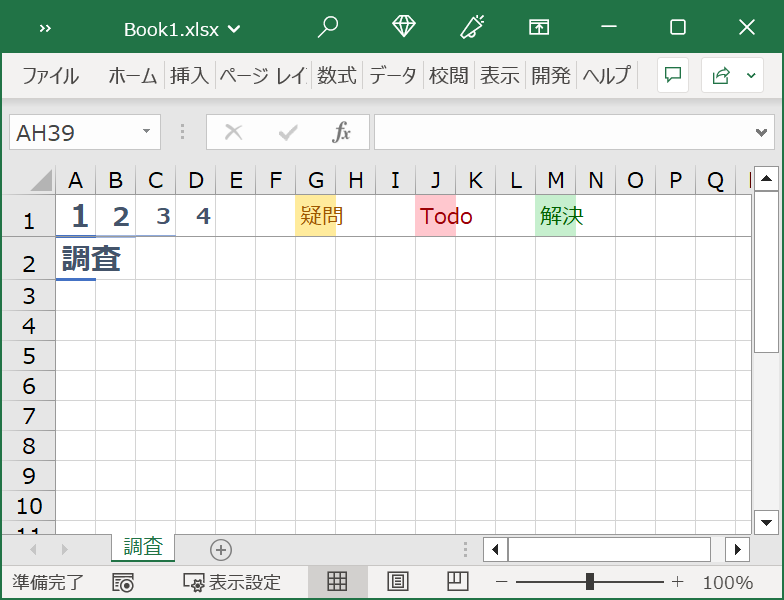
コード
Sub 作業用シート作成() ' シートのすべてのセルの幅を設定 Cells.ColumnWidth = 2.2 ' 見出しのスタイルと値を設定 With Range("A1") .Style = "見出し 1" .Value = "1" End With With Range("B1") .Style = "見出し 2" .Value = "2" End With With Range("C1") .Style = "見出し 3" .Value = "3" End With With Range("D1") .Style = "見出し 4" .Value = "4" End With ' 疑問のセルを設定 With Range("G1") .Value = "疑問" .Style = "どちらでもない" End With ' Todoのセルを設定 With Range("J1") .Value = "Todo" .Style = "悪い" End With ' 解決のセルを設定 With Range("M1") .Value = "解決" .Style = "良い" End With ' 2行目を固定 Rows("2:2").Select ActiveWindow.FreezePanes = True ' A2セルにシート名を出力 Range("A2").FormulaR1C1 = "=MID(CELL(""filename"",R1C1),FIND(""]"",CELL(""filename"",R1C1))+1,99)" ' A2セルのスタイルを"見出し 1"に変更 Range("A2").Style = "見出し 1" ' 最後にA2セルを選択 Range("A2").Select End Sub
シート名表示のところの補足
FormulaR1C1プロパティは、R1C1形式の参照を使った数式を設定するためのプロパティです。
R1C1形式は、行番号と列番号をR(行)とC(列)で表現する形式で、A1形式とは異なります。
例えば、A1形式のセル参照A1は、R1C1形式ではR1C1と表されます。
A1形式では、Aが1列目を示し、1が1行目を示します。
一方、R1C1形式では、R1が1行目を示し、C1が1列目を示します。
このため、以下の数式で使用されているA1をR1C1形式に変換する必要がありました。
=MID(CELL("filename",A1),FIND("]",CELL("filename",A1))+1,99)
この数式をR1C1形式に変換すると、以下のようになります。
=MID(CELL("filename",R1C1),FIND("]",CELL("filename",R1C1))+1,99)
この変換により、数式がFormulaR1C1プロパティを使って適切に設定されます。
シェルワンライナー #2.1.e クォートと変数
1. 2.1.e. クォートと変数
- awkを使う際に引数に与えるAWKコードを シングルクォート(
'') で囲っていたが、これには2つ意味がある{print 1+1}の様に空白の入った引数を一つにまとめて引き渡し{printと1+1}の2つの引数として渡さない
$1などのAWKの変数が、シェルの変数として解釈されることを防止
- 特殊な場合を除き、Bashでは
''で囲われた文字に手を加えない - 逆にいうと、引数にbashの変数を使いたいときはクォートしては駄目ということ
- 話変わって、シェルスクリプトは変数を使うときに、ダブルクォートで囲うかどうかでシェルスクリプトの挙動が変わるパターンあり。
${変数名}と{}で変数名を囲う表記が用意されている
1.1. 練習問題
1.1.1. 問題と答え
----準備---- $ p=pen $ re="" #←変数reの文字列は長さ0の空文字になる ----ここから答え---- #1 $ echo $p "$p" '$p' pen pen $p #2 $ echo "This is a ${p}cil" 'That is a $p.' This is a pencil That is a $p. #3 $ echo "This is a ${p}cil." That is a "$p"cil. "That was a $pcil." This is a pencil. That is a pencil. That was a . #4-1 $ grep "$re" /etc/passwd root:x:0:0:root:/root:/bin/bash daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin bin:x:2:2:bin:/bin:/usr/sbin/nologin sys:x:3:3:sys:/dev:/usr/sbin/nologin ... #4-2 $ grep $re /etc/passwd 止まった...